Your support inbox is full. Tickets keep moving. Someone on the team is answering DMs, email, live chat, and maybe a chatbot is handling the easy questions. Yet revenue doesn't clearly move, repeat purchase behavior feels inconsistent, and you still can't say whether support is helping the business or just absorbing problems.
That's the trap. A busy queue can look like good service when it's really just a record of unresolved friction.
The evaluation of customer service matters because speed alone isn't enough, but it does set the baseline. Existing guidance often misses AI support even though 32% of customers now resolve issues via AI without human help and 49% believe it improves customer experience, while 69% define good service by its speed, according to Indeed's overview of evaluating customer service. Shopify merchants feel that gap in real time. They adopt automation, but they still don't have a practical way to judge whether it's improving the customer journey.
Table of Contents
- Beyond the Inbox An Introduction to Service Evaluation
- The Two Sides of Service Quality Numbers and Narratives
- Essential KPIs for E-commerce Customer Service
- A Step-by-Step Framework for Service Evaluation
- Automating Evaluation and Improvement with AI and Carti
- From Insights to Action Turning Evaluation into Revenue
Beyond the Inbox An Introduction to Service Evaluation
For most Shopify stores, customer service starts as a reactive function. Someone answers “Where's my order?”, “Will this fit?”, “Can I change my shipping address?” and “Why didn't my discount work?” If the team replies fast enough, it feels like the job is getting done.
That standard is too low.
Customer service is one of the few operating functions that sits directly between buyer intent and buyer hesitation. It affects conversion before purchase, confidence during checkout, and trust after delivery. If you only evaluate output volume, you miss the core question. Did the interaction remove friction, protect the order, and increase the odds of another purchase?
Practical rule: Don't grade support by activity. Grade it by whether the customer got unstuck.
For a growing store, the evaluation of customer service should answer four business questions:
- Did we resolve the issue quickly enough to keep the sale alive?
- Did we answer accurately enough to avoid repeat contact?
- Did we create enough confidence for the customer to buy again?
- Did we learn anything that should change the site, policy, or product page?
That last point gets ignored most often. Support isn't only a service channel. It's a live feed of merchandising problems, policy confusion, product objections, and checkout friction.
A store that evaluates service well doesn't just coach agents better. It updates FAQ copy, rewrites return policy pages, fixes product detail gaps, and reduces the number of preventable tickets in the first place. That's where support stops being a cost center and starts functioning like an operating advantage.
The Two Sides of Service Quality Numbers and Narratives
A useful evaluation system has two parts. The first is quantitative. The second is qualitative. Often, there is an overreliance on one, with the other being neglected.
Picture a doctor's visit. Vital signs tell you whether something is off. The conversation tells you why.
What the numbers tell you
Metrics show pattern, scale, and direction. They tell you whether service is fast, whether customers are satisfied, and whether problems are getting resolved.
One metric stands above the rest for operational usefulness. First Contact Resolution, or FCR, is the #1 driver of customer loyalty, according to Talkdesk's customer service statistics. The reason is simple. Customers don't judge support by effort expended behind the scenes. They judge it by whether the problem ended.
That makes poor resolution expensive. 61% of customers will switch to a competitor after one negative experience, which means a support failure doesn't just create one unhappy ticket. It can end the relationship entirely.
Here's the practical use of quantitative evaluation. It helps you spot where the system is breaking:
- Low FCR often means policy ambiguity, poor knowledge access, or inaccurate answers.
- Weak CSAT often points to tone problems, slow response, or unresolved edge cases.
- Long response times usually expose staffing issues, channel overload, or poor triage.
- Spikes in repeat contacts usually mean customers are getting partial answers instead of final answers.
What the narratives reveal
The numbers tell you what moved. Ticket reviews tell you why it moved.
A customer may leave a low score because the answer was technically correct but delivered too late for a same-day purchase. Another may leave a positive score even though the underlying issue came from a broken product page. If you only read dashboards, you miss the difference between agent failure and business failure.
That's why every evaluation system needs direct review of conversations across chat, email, social, and self-service logs.
| Aspect | Quantitative (The Numbers) | Qualitative (The Narratives) |
|---|---|---|
| Primary role | Shows trends and performance levels | Explains causes and customer context |
| Best use | Tracking consistency over time | Finding friction behind the scores |
| Typical inputs | CSAT, FCR, response time, repeat contacts | Ticket reviews, chat transcripts, customer comments |
| Main strength | Easy to compare week to week | Exposes nuance and root causes |
| Main limitation | Can hide context | Harder to scale without a rubric |
| Questions answered | What happened? How often? | Why did it happen? What should change? |
A support dashboard can tell you that service slipped. A transcript can tell you the size guide was missing the one detail shoppers needed.
In practice, the strongest teams combine both. They watch the score trend, then inspect real interactions from the same period. That's how you separate a training issue from a broken process, or a product problem from a support problem.
Essential KPIs for E-commerce Customer Service
A shopper opens chat at 4:12 p.m. to ask whether a product will arrive before the weekend. If the answer comes at 6:03, the ticket may still be marked "handled," but the sale is already gone. That is why support measurement for Shopify stores has to connect service performance to buying moments, not just inbox activity.

The core metrics worth tracking
Keep the scorecard tight. Four service KPIs do most of the operational work for an e-commerce team: CSAT, FRT, FCR, and repeat contact rate. Together, they show whether customers got help, how fast they got it, whether the issue was resolved effectively, and whether your team is creating extra demand by giving incomplete answers.
CSAT measures the customer's reaction to the interaction. It is useful, but it is easy to overrate. A friendly agent can earn a high score even when the refund policy is confusing or the shipping promise was unrealistic. Use CSAT as a read on perceived quality, not proof that the underlying process is healthy.
FRT, or first response time, matters most during pre-purchase and post-purchase moments with urgency attached. Size questions, delivery cutoffs, order edits, ingredient concerns, and exchange requests all carry conversion risk. A slow first reply does more than frustrate people. It reduces the chance that the order happens at all, and it weakens cart recovery when shoppers are waiting for reassurance before buying.
FCR should be one of the first numbers reviewed each week. If the issue ends in one interaction, cost stays low and confidence stays high. If it takes three touches across chat and email, support expense rises, queue pressure increases, and the customer starts to doubt the brand.
Then track repeat contacts to catch false positives. A helpdesk can show a fast response and a closed ticket while the same customer comes back through Instagram, email, or chat because the answer was partial, generic, or disconnected from the order details.
A simple operating formula keeps the team aligned:
- FCR formula: (FCR tickets / Total FCR-eligible tickets) × 100
- CSAT formula: satisfied responses / total survey responses
- FRT formula: time from customer message to first team response
- Repeat contact rate: customers who recontact support on the same issue / total relevant issues
For stores that already review retention and lifecycle performance alongside support, this guide to strategies for improved customer success pairs well with service metrics.
How to use KPIs without getting lost in dashboards
The point of a KPI is action.
Teams that struggle with evaluation usually have one of two problems. They either track too little and miss obvious failure patterns, or they track too much and bury the signal under vanity reporting. For Shopify operators, the better approach is a two-layer view: one dashboard for what needs attention today, and one for what needs fixing this week.
The daily dashboard should help a support lead answer practical questions fast. Where is the backlog building? Which channel is slowing down? Which issues are stalling orders or creating refund risk?
- Daily operations view
- Open volume: what is waiting now
- FRT by channel: where shoppers are waiting longest
- Escalations: which issues frontline support cannot close
- Pre-purchase conversations: which active chats or emails may affect conversion today
The weekly dashboard should be narrower and more diagnostic. It should help the team decide what to change in macros, policy, training, product information, and automation.
- Weekly quality view
- FCR trend: whether support is resolving issues cleanly
- CSAT trend: whether customers feel the experience is improving
- Top contact reasons: what is driving avoidable demand
- Repeat contacts: where answers are incomplete or inconsistent
- Revenue-linked tickets: which support themes correlate with abandoned carts, canceled orders, or return requests
For teams building a wider measurement model across the store, this overview of e-commerce key performance indicators helps place support metrics alongside conversion, retention, and revenue reporting.
Track the metrics that change staffing, content, automation, or policy. Ignore the ones that only make the report look finished.
A Step-by-Step Framework for Service Evaluation
At 2:15 p.m., live chat is stacked with pre-purchase sizing questions, email is filling with “where is my order?” tickets, and a shopper who started on Instagram DMs has now emailed support after abandoning a cart. If those interactions are measured in separate places, the team misses what matters most. Which conversations are slowing revenue, which ones are creating refund risk, and which answers are inconsistent enough to trigger repeat contacts?
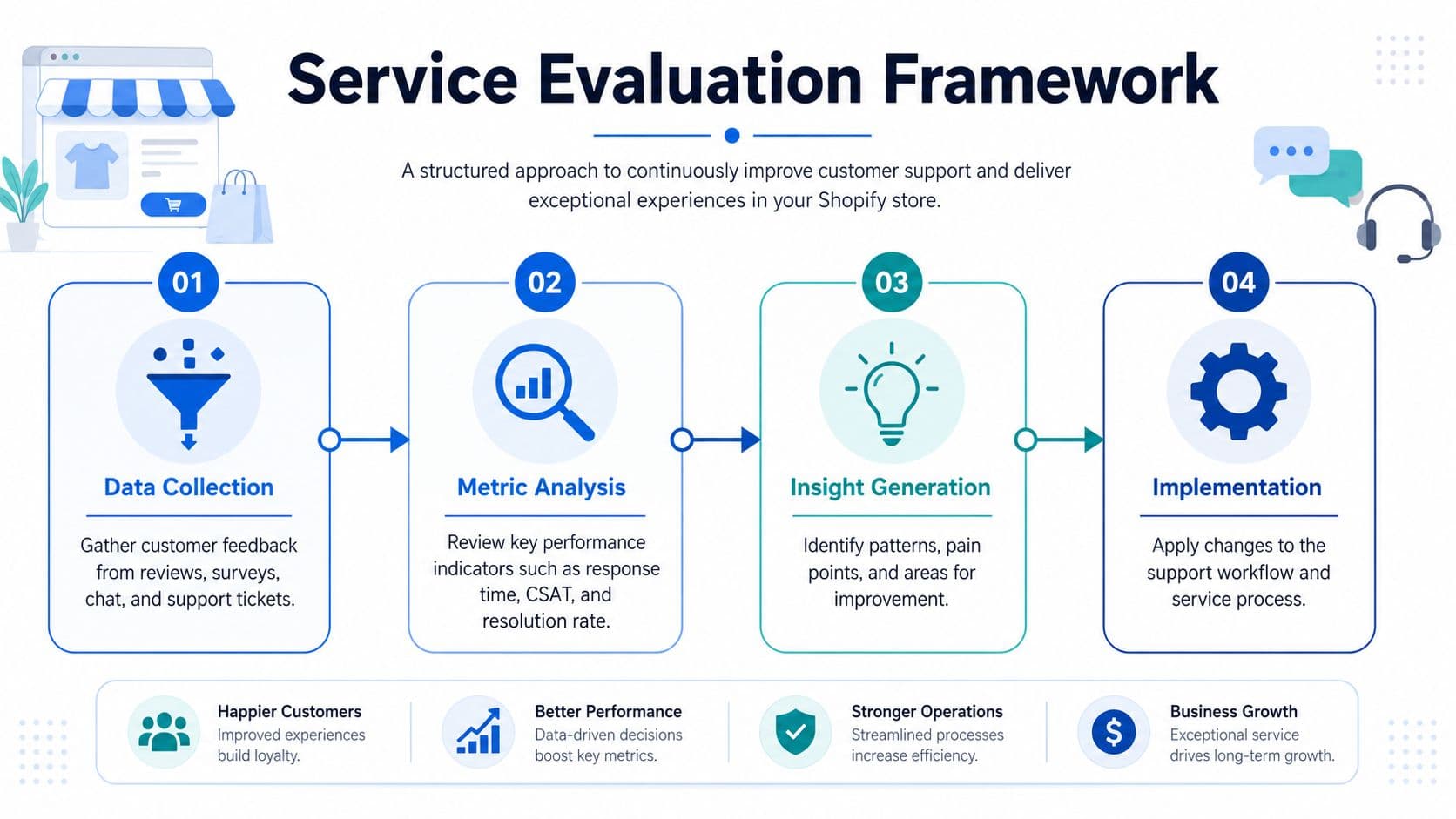
Start with one source of truth
For a Shopify brand, service evaluation starts by joining the systems where customer conversations happen. Pull from your helpdesk, Shopify order data, chat logs, social DMs, and any self-service or bot transcripts.
The goal is not a polished BI project. The goal is one operating view that lets a support lead or founder answer practical questions quickly. What are shoppers asking before they buy? Where are replies too slow for the buying moment? Which issues get resolved in one touch, and which ones keep bouncing across channels? As noted earlier, customers expect fast replies and consistent service across channels. That expectation directly affects conversion, retention, and whether a hesitant shopper comes back to finish checkout.
Channel consistency deserves special attention here. A store can look strong on average response time and still lose sales if chat gives one answer, email gives another, and social gets ignored until the next day. Evaluation has to catch that.
Score a representative sample
Reviewing only escalations produces bad management decisions. It overweights dramatic failures and hides the routine interactions that shape most of the customer experience.
Sample tickets and chats across the parts of the journey that matter commercially:
- Pre-purchase questions such as fit, delivery timing, compatibility, stock availability, or ingredients
- Post-purchase issues such as tracking confusion, exchanges, returns, damaged items, or missing orders
- Cross-channel conversations where the same customer contacts support more than once in different places
- Near-miss conversations where the reply looked acceptable internally but the customer still failed to buy, canceled, or contacted support again
Many teams err by scoring for politeness and speed, overlooking whether the answer helped the customer make progress. In e-commerce, quality has to include commercial awareness. A rep should know when to clarify a return policy, when to reassure a hesitant buyer, and when to stop pushing because the issue is operational, not sales-related.
Use a short scorecard that managers will apply consistently:
| Category | What to check |
|---|---|
| Accuracy | Was the information correct and aligned with policy, inventory, and fulfillment reality? |
| Resolution | Did the interaction solve the issue fully, or did it create likely repeat contact? |
| Speed | Was the reply fast enough for the customer's context and channel? |
| Tone | Did the message reduce friction, build trust, and fit the brand? |
| Commercial awareness | Did the rep protect or support revenue when appropriate without forcing a sale? |
Review normal conversations every week. That is where process failures, content gaps, and cart-killing hesitation usually show up first.
For teams formalizing this process, SnapDial's guide to optimizing customer support performance is useful for thinking through scorecards and review discipline.
Connect service quality to store outcomes
A service evaluation system is incomplete if it stops at ticket quality. Strong operators connect support interactions to what happened next.
Check whether the customer purchased, canceled, requested a refund, returned the item, or contacted support again. Look at patterns by issue type. Delivery questions that end in abandoned carts point to weak policy copy or unclear PDP messaging. Repeated compatibility questions often mean product pages are doing too little work before the sale. Slow replies on chat during peak traffic can become a conversion problem, not just a support problem.
This is also where AI starts to pay for itself. If you are mapping how support quality affects conversion and recovery, this guide to using an AI chatbot for ecommerce is a useful reference for handling common questions faster while capturing cleaner evaluation data.
Turn findings into weekly decisions
Evaluation matters when it changes how the store runs the next week.
A useful review meeting asks a short set of hard questions:
- What contact reason should disappear if we fix the site or policy copy?
- Which support failure came from bad information upstream, not poor agent execution?
- Which issue type is costing orders or increasing return risk?
- Where are channel handoffs creating customer effort and lost context?
- Which macro, workflow, or automation should be rewritten based on what we reviewed?
Then assign work to the right owner. Support can flag the problem, but merchandising, operations, growth, and product often need to fix it.
A few examples:
- If shoppers keep asking about delivery dates, update shipping language on product pages, in cart, and inside support templates
- If fit questions stall checkout, improve size guidance, add comparison notes, and train support to answer with product-specific context
- If return confusion keeps driving repeat contacts, rewrite the return policy in plain language and mirror that wording across every channel
- If one SKU generates abnormal complaint volume, pause aggressive promotion until product quality or expectation mismatch is addressed
The best service evaluation systems are simple enough to run every week and sharp enough to change revenue outcomes. They reduce avoidable contacts, improve conversion support, and show exactly where AI, automation, or site content should do more of the work.
Automating Evaluation and Improvement with AI and Carti
Manual review still matters, but manual-only systems break as volume rises. They're slow, inconsistent, and expensive to maintain. AI changes that by shrinking the gap between interaction, evaluation, and improvement.
What AI should automate first
Start with the work that humans are least well suited to do repeatedly:
- Instant first responses for common pre-purchase and post-purchase questions
- Conversation tagging so recurring issues surface automatically
- Resolution tracking by issue type and channel
- Root-cause clustering so you can see where site content, policy wording, or product information is weak
Modern quality systems are evolving in this direction. If you're rethinking QA design in AI-heavy environments, Vatis Tech has a good perspective on modernizing contact center quality assurance.
For merchants evaluating AI specifically, don't ask only whether the bot answered. Ask whether it reduced repeat contacts, preserved buying momentum, and created a reliable feedback loop into site improvements. This guide to an AI chatbot for ecommerce is useful if you're comparing that role against traditional live chat.
The metric to watch most closely is still FCR. For AI chatbots, top performers achieve FCR rates of 85%, and high FCR correlates with a 25-30% reduction in repeat contacts and a 15-20% reduction in operational costs, according to Lorikeet's article on customer service metrics. The same source notes that a 10% improvement in FCR can lead to a 5-7% increase in customer retention.
That is the primary argument for automation. Good AI doesn't just answer faster. It prevents the second ticket.
Where automation changes the economics of support
An AI system becomes more valuable when it does three jobs at once. It handles routine demand, measures service quality in the background, and reveals buying friction that the rest of the business should fix.
In e-commerce, that matters because support is often mixed with selling. A shopper asking about shade match, material, bundle compatibility, or delivery timing isn't only seeking help. They're deciding whether to buy.
When AI can respond instantly, surface the top unresolved themes, and identify where shoppers drop into hesitation, service evaluation stops being a backward-looking report. It becomes a live operating system.
A short walkthrough helps make that concrete:
The most useful pattern is this one:
| Support signal | What it usually means | Operational response |
|---|---|---|
| High volume of repetitive questions | Site copy or policy language is weak | Update FAQ, PDPs, and policy pages |
| Fast reply but low resolution | Automation is answering without solving | retrain flows and tighten answer logic |
| Repeat questions before checkout | Buyer hesitation is blocking conversion | add proactive guidance and product education |
| Frequent policy clarifications | store rules are hard to understand | rewrite customer-facing language |
The best AI support setup doesn't replace evaluation. It performs it continuously.
From Insights to Action Turning Evaluation into Revenue
The evaluation of customer service only matters if it changes buyer outcomes.
If support reviews show repeated confusion around shipping cutoffs, fix the shipping page, add the answer to product pages where urgency matters, and update your automated responses. If customers keep asking whether two products work together, that's a merchandising problem. Build a bundle page, add compatibility notes, and make the answer visible before the question is asked.
If CSAT drops after a new launch, don't assume the team suddenly performed worse. Read the transcripts. You may find that the product page oversold ease of use, the care instructions were unclear, or delivery expectations didn't match fulfillment reality.
A practical revenue lens helps sort actions:
- Protect conversion: Resolve pre-purchase uncertainty fast
- Protect margin: Reduce avoidable contacts and repeat handling
- Protect retention: Fix service failures that erode trust after the order
- Improve merchandising: Use support data to rewrite weak pages and policies
At this stage, support and retention begin to overlap. Post-purchase questions often reveal whether the customer feels reassured or abandoned after checkout. That behavior shapes repeat buying, review sentiment, and referral potential. This overview of post-purchase behavior is helpful if you want to connect service evaluation more tightly to retention decisions.
Good operators treat support conversations as commercial signals. A question about returns may signal distrust. A question about materials may signal purchase intent. A question about “where is my order” may signal a communication gap, not a logistics failure.
When you evaluate service that way, you stop measuring a department and start managing a growth lever.
Carti helps Shopify stores turn support into sales by answering shopper questions instantly, surfacing recurring friction, and recovering revenue that would otherwise slip away. If you want a faster way to automate evaluation and improve service quality around the clock, take a look at Carti.

Written by
Daniel AndersonFounder of Carti. 10+ years building ecommerce brands in apparel and supplements. Still runs a Shopify store and built Carti to help merchants convert more browsers into buyers.
Ready to boost your store's sales?
Install Carti in 5 minutes and let AI handle customer questions, recommend products, and close sales 24/7.
Start Free Trial14-day free trial